原文链接:
疯狂的技术宅告诉你前端开发为什么要用 Node.jsjuejin.im
九种基本类型及封装类
基本类型booleanbytecharshortintlongdoublevoid
二进制位数
8(一字节)
16(2字节)
16(2字节)
32(4字节)
64(8字节)
64(8字节)
--
封装器类
Boolean
Byte
Character
Short
Integer
Long
Double
Void
switch语句后的控制表达式只能是short、char、int、long整数类型和枚举类型,不能是float,double和boolean类型。String类型是java7开始支持。
位运算符
-5右移3位后结果为-1,-1的二进制为:
1111 1111 1111 1111 1111 1111 1111 1111 // (用1进行补位)
-5无符号右移3位后的结果 536870911 换算成二进制:
0001 1111 1111 1111 1111 1111 1111 1111 // (用0进行补位)
应用:不用临时变量交换两个数
void swap(int argc, char *argv[])
{
a = a ^ b;
b = b ^ a;
a = a ^ b;
}
for循环,ForEach,迭代器效率
直接for循环效率最高,其次是迭代器和 ForEach操作。
其实ForEach 编译成字节码之后,使用的是迭代器实现的。
synchronized和volatile
volatile仅能使用在变量级别;synchronized则可以使用在变量、方法、和类级别的。
volatile保证了变量的可见性,synchronized保证了原子性和可见性。
volatile
原理:首先我们要先意识到有这样的现象,编译器为了加快程序运行的速度,对一些变量的写操作会先在寄存器或者是CPU缓存上进行,最后才写入内存。而在这个过程,变量的新值对其他线程是不可见的,而volatile的作用就是使它修饰的变量的读写操作都必须在内存中进行。volatile告诉JVM, 它所修饰的变量不保留拷贝,直接访问主内存中的。
volatile与synchronized
volatile不能保证原子性原因:线程A修改了变量还没结束时,另外的线程B可以看到已修改的值,而且可以修改这个变量,而不用等待A释放锁,因为Volatile 变量没上锁。
注意
声明为volatile的简单变量如果当前值由该变量以前的值相关,那么volatile关键字不起作用。
也就是说如下的表达式都不是原子操作:
也就是说如下的表达式都不是原子操作:
n = n + 1 ;
n ++ ;
只有当变量的值和自身上一个值无关时对该变量的操作才是原子级别的,如n = m + 1。
Java内存模型的抽象(volatile)
在java中,所有实例域、静态域和数组元素存储在堆内存中,堆内存在线程之间共享(本文使用“共享变量”这个术语代指实例域,静态域和数组元素)。局部变量,方法定义参数和异常处理器参数不会在线程之间共享,在栈内存中,不需要同步处理,因为栈内存是线程独享的,它们不会有内存可见性问题,也不受内存模型的影响。
Java线程之间的通信由Java内存模型(本文简称为JMM)控制,JMM决定一个线程对共享变量的写入何时对另一个线程可见。从抽象的角度来看,JMM定义了线程和主内存之间的抽象关系:线程之间的共享变量存储在主内存(main memory)中,每个线程都有一个私有的本地内存(local memory),本地内存中存储了该线程以读/写共享变量的副本(寄存器或CPU缓存)本地内存是JMM的一个抽象概念,并不真实存在。它涵盖了缓存,写缓冲区,寄存器以及其他的硬件和编译器优化。Java内存模型的抽象示意图如下:
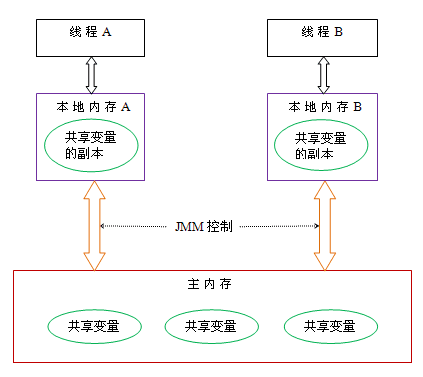
java内存模型
从上图来看,线程A与线程B之间如要通信的话,必须要经历下面2个步骤:
下面通过示意图来说明这两个步骤:
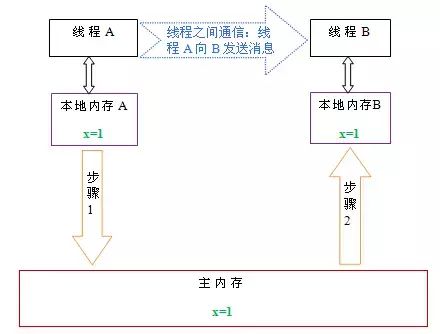
如上图所示,本地内存A和B有主内存中共享变量x的副本。假设初始时,这三个内存中的x值都为0。线程A在执行时,把更新后的x值(假设值为1)临时存放在自己的本地内存A中。当线程A和线程B需要通信时,线程A首先会把自己本地内存中修改后的x值刷新到主内存中,此时主内存中的x值变为了1。随后,线程B到主内存中去读取线程A更新后的x值,此时线程B的本地内存的x值也变为了。
从整体来看,这两个步骤实质上是线程A在向线程B发送消息,而且这个通信过程必须要经过主内存。JMM通过控制主内存与每个线程的本地内存之间的交互,来为java程序员提供内存可见性保证。
equals与==的区别
==常用于比较原生类型,而equals()方法用于检查对象的相等性。另一个不同的点是:如果==和equals()用于比较对象,当两个引用地址相同,== 返回true。而equals()可以返回true或者false主要取决于重写实现。最常见的一个例子,字符串的比较,不同情况==和equals()返回不同的结果。
看Object源码:
public boolean equals(Object obj) {
return (this == obj);
}
==表示的是比较两个对象实例的内存地址是否相同。如果不重写equal(),就和==等效,
术语来讲的区别:
hashCode作用
以java.lang.Object来理解JVM每new一个Object,它都会将这个Object丢到一个Hash哈希表中去,这样的话,下次做Object的比较或者取这个对象的时候,它会根据对象的hashcode再从Hash表中取这个对象。这样做的目的是提高取对象的效率。
具体过程是这样:
java.lang.Object中对hashCode的约定:
Object的公用方法
notify
notifyAll
Java四种引用 --- 这里指的是“引用“,不是对象
强引用
平常我们使用对象的方式Object object = new Object();如果一个对象具有强引用,它就不会被垃圾回收器回收。即使当前内存空间不足,JVM也不会回收它,而是抛出OutOfMemoryError错误,使程序异常终止。例如下面的代
public class Main {
public static void main(String[] args) {
new Main().fun1();
}
public void fun1() {
Object object = new Object();
Object[] objArr = new Object[1000];
}
}
当运行至Object[] objArr = new Object[1000];这句时,如果内存不足,JVM会抛出OOM错误也不会回收object指向的对象。不过要注意的是,当fun1运行完之后,object和objArr都已经不存在了,所以它们指向的对象都会被JVM回收。
但如果想中断强引用和某个对象之间的关联,可以显式地将引用赋值为null,这样一来的话,JVM在合适的时间就会回收该对象。
软引用
软引用通过SoftReference创建,在使用软引用时,如果内存的空间足够,软引用就能继续被使用,而不会被垃圾回收器回收,只有在内存不足时,软引用才会被垃圾回收器回收。
软引用的这种特性使得它很适合用来解决OOM问题,实现缓存机制,例如:图片缓存、网页缓存等等……
软引用可以和一个引用队列(ReferenceQueue)联合使用,如果软引用所引用的对象被JVM回收,这个软引用就会被加入到与之关联的引用队列中。
弱引用
事实上软引用和弱引用非常类似,两者的区别在于:只具有弱引用的对象拥有的生命周期更短暂。因为当 JVM 进行垃圾回收,一旦发现弱引用对象,无论当前内存空间是否充足,都会将弱引用回收。不过由于垃圾回收器是一个优先级较低的线程,所以并不一定能迅速发现弱引用对象。
弱引用可以和一个引用队列(ReferenceQueue)联合使用,如果弱引用所引用的对象被JVM回收,这个弱引用就会被加入到与之关联的引用队列中。
虚引用
虚引用”顾名思义,就是形同虚设,与其他几种引用都不同,虚引用并不会影响对象的生命周期。如果一个对象仅持有虚引用,那么它相当于没有引用,在任何时候都可能被垃圾回收器回收。
小结
引用和引用队列提供了一种通知机制,允许我们知道对象已经被销毁或者即将被销毁。GC要回收一个对象的时候,如果发现该对象有软、弱、虚引用的时候,会将这些引用加入到注册的引用队列中。软引用和弱引用差别不大,JVM都是先把SoftReference和WeakReference中的referent字段值设置成null,之后加入到引用队列;而虚引用则不同,如果某个堆中的对象,只有虚引用,那么JVM会将PhantomReference加入到引用队列中,JVM不会自动将referent字段值设置成null。
实际应用:利用软引用和弱引用缓存解决OOM问题。
如:Bitmap的缓存
设计思路是:用一个HashMap来保存图片的路径和相应图片对象(Bitmap)的软引用之间的映射关系,在内存不足时,JVM会自动回收这些缓存图片对象所占用的空间,从而有效地避免了OOM的问题。在Android开发中对于大量图片下载会经常用到。
wait()、notify()和sleep()
wait()和notify()
public static void firstMethod(){
synchronized (a){
System.out.println(Thread.currentThread().getName() + " firstMethod--死锁");
try {
// Thread.sleep(10);
a.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (b){
System.out.println(Thread.currentThread().getName() + " firstMethod--解锁");
}
}
}
public static void seconedMethod(){
synchronized (b){
System.out.println(Thread.currentThread().getName() + " seconedMethod--死锁");
synchronized (a){
System.out.println(Thread.currentThread().getName() + " seconedMethod--解锁");
a.notify();
}
}
}
如果用两个线程分别执行这两个方法
public static void main(String[] args) {
Runnable runnable1 = new Runnable() {
@Override
public void run() {
firstMethod();
}
};
Runnable runnable2 = new Runnable() {
@Override
public void run() {
seconedMethod();
}
};
Thread thread1 = new Thread(runnable1);
Thread thread2 = new Thread(runnable2);
thread1.start();
thread2.start();
}
如果是用sleep方法替换掉wait方法,就是一个死锁,线程thread1先执行拿到a对象的锁,然后阻塞10ms(并没有释放锁),thread2然后拿到对象b的锁,这时候seconedMethod需要a对象的锁,但是firstMethod并没有释放,然后10ms过后,firstMethod需要b的锁,然后b的锁也没有在seconedMethod方法中释放,两个线程相互等待对方释放锁,就形成了死锁。
运行结果:
Thread-0 firstMethod--死锁
Thread-1 seconedMethod--死锁
如果不使用sleep而是使用wait方法,就不会发生死锁。因为wait释放了firstMethod中的a对象的锁,当seconedMethod需要a对象锁的时候就可以用了。
运行结果:
Thread-0 firstMethod--死锁
Thread-1 seconedMethod--死锁
Thread-1 seconedMethod--解锁
Thread-0 firstMethod--解锁
notify():唤醒在此对象监视器上等待的单个线程。如果所有线程都在此对象上等待,则会选择唤醒其中一个线程(随机)。直到当前的线程放弃此对象上的锁,才能继续执行被唤醒的线程。
sleep()
通过Thread.sleep()使当前线程暂停执行一段时间,让其他线程有机会继续执行,但它并不释放对象锁。也就是说如果有synchronized同步块,其他线程仍然不能访问共享数据。注意该方法要捕捉异常。
public class ThreadLock {
Object lock = new Object();
int num = 0;
public static void main(String[] args) {
ThreadLock test = new ThreadLock();
Runnable runnable = new Runnable() {
@Override
public void run() {
test.method2();
}
};
Thread thread1 = new Thread(runnable);
thread1.start();
test.method1();
}
public void method1(){
synchronized (lock){
try {
Thread.sleep(1000);
// lock.wait(1000);
num += 100;
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public void method2(){
synchronized (lock){
num += 9;
System.out.println(num);
}
}
}因为在main线程调用方法,因此先执行主线程的method1,对象锁被主线程拿走了,那么子线程执行method2的时候就需要等待1秒后把锁还回来。
1秒后输出结果:
109
如果替换成lock.wait(1000);
lock.wait(1000)会让当前线程(main线程)睡眠1秒,同时释放synchronized的对象锁,因此小于1秒输出9
synchronized和lock
几个概念
synchronized
特点:
lock
lock提供了如下的方法:
synchronized和lock区别
public class ThreadLock {
public static void main(String[] args) {
Test test = new Test();
Lock lock = new ReentrantLock();
Runnable runnable = new Runnable() {
@Override
public void run() {
lock.lock();
for (int i = 0; i < 50 ; i++) {
test.setX(1);
System.out.println(Thread.currentThread().getName() + " : " +test.getX());
}
lock.unlock();
}
};
Thread thread1 = new Thread(runnable);
Thread thread2 = new Thread(runnable);
thread1.start();
thread2.start();
}
static class Test{
private int x = 100;
public int getX(){
return x;
}
public void setX(int y){
x = x - y;
}
}
}
ReentrantLock与synchronized的比较
ReentrantLocak(可重入锁)
简单来说,它有一个与锁相关的获取计数器,如果拥有锁的某个线程再次得到锁,那么获取计数器就加1,然后锁需要被释放两次才能获得真正释放。
ReentrantLock提供了synchronized类似的功能和内存语义。
不同
缺点
ArrayList,LinkedList和Vector
HashMap和HashTable
ConcurrentHashMap
锁分段技术
HashTable容器在竞争激烈的并发环境下表现出效率低下的原因是所有访问HashTable的线程都必须竞争同一把锁,那假如容器里有多把锁,每一把锁用于锁容器其中一部分数据,那么当多线程访问容器里不同数据段的数据时,线程间就不会存在锁竞争,从而可以有效的提高并发访问效率,这就是ConcurrentHashMap所使用的锁分段技术,首先将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。
HashSet
实现了Set接口,HashSet本质就是一个HashMap,把HashMap的key作为HashSet的值,HashMap的value是一个固定的Object对象,因为HashMap的key是不允许重复的,所以HashSet里的元素也是不能重复的,也可以看出HashSet的查询效率很高。
String,StringBuilder和StringBuffer
Excption与Error包结构
结构图:
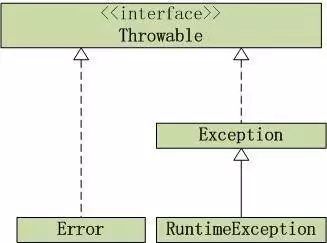
结构图
Throwable
Exception
RuntimeException
Error
Interface与abstract类的区别
参数抽象类接口
默认的方法实现
它可以有默认的方法实现
接口完全是抽象的。它根本不存在方法的实现
实现
子类使用extends关键字来继承抽象类。如果子类不是抽象类的话,它需要提供抽象类中所有声明的方法的实现。
子类使用关键字implements来实现接口。它需要提供接口中所有声明的方法的实现
构造器
抽象类可以有构造器
接口不能有构造器
与正常Java类的区别
除了你不能实例化抽象类之外,它和普通Java类没有任何区别
接口是完全不同的类型
访问修饰符
抽象方法可以有public、protected和default这些修饰符
接口方法默认修饰符是public。你不可以使用其它修饰符。
main方法
抽象方法可以有main方法并且我们可以运行它
接口没有main方法,因此我们不能运行它。
多继承
抽象类可以继承一个类和实现多个接口
接口只可以继承一个或多个其它接口
速度
它比接口速度要快
接口是稍微有点慢的,因为它需要时间去寻找在类中实现的方法。
添加新方法
如果你往抽象类中添加新的方法,你可以给它提供默认的实现。因此你不需要改变你现在的代码。
如果你往接口中添加方法,那么你必须改变实现该接口的类。
静态内部类和非静态内部类
相同点
不同点
泛型擦除
一篇好博客
泛型在JDK5以后才有的,擦除是为了兼容之前没有的使用泛型的类库和代码。如:ArrayList和ArrayList在编译器编译的时候都变成了ArrayList。
List<Integer> list = new ArrayList<Integer>();
Map<Integer, String> map = new HashMap<Integer, String>();
System.out.println(Arrays.toString(list.getClass().getTypeParameters()));
System.out.println(Arrays.toString(map.getClass().getTypeParameters()));
/* Output
[E]
[K, V]
*/
我们期待的是得到泛型参数的类型,但是实际上我们只得到了一堆占位符。
public class Main {
public T[] makeArray() {
// error: Type parameter 'T' cannot be instantiated directly
return new T[5];
}
}
我们无法在泛型内部创建一个T类型的数组,原因也和之前一样,T仅仅是个占位符,并没有真实的类型信息,实际上,除了new表达式之外,instanceof操作和转型(会收到警告)在泛型内部都是无法使用的,而造成这个的原因就是之前讲过的编译器对类型信息进行了擦除。
public class Main {
private T t;
public void set(T t) {
this.t = t;
}
public T get() {
return t;
}
public static void main(String[] args) {
Main m = new Main();
m.set("findingsea");
String s = m.get();
System.out.println(s);
}
}
/* Output
findingsea
*/
虽然有类型擦除的存在,使得编译器在泛型内部其实完全无法知道有关T的任何信息,但是编译器可以保证重要的一点:内部一致性,也是我们放进去的是什么类型的对象,取出来还是相同类型的对象,这一点让Java的泛型起码还是有用武之地的。
代码片段展现就是编译器确保了我们放在T上的类型的确是T(即便它并不知道有关T的任何类型信息)。这种确保其实做了两步工作:
这两步工作也成为边界动作。
public class Main {
public List fillList(T t, int size) {
List list = new ArrayList();
for (int i = 0; i < size; i++) {
list.add(t);
}
return list;
}
public static void main(String[] args) {
Main m = new Main();
List list = m.fillList("findingsea", 5);
System.out.println(list.toString());
}
}
/* Output
[findingsea, findingsea, findingsea, findingsea, findingsea]
*/
代码片段同样展示的是泛型的内部一致性。
擦除的补偿
如上看到的,但凡是涉及到确切类型信息的操作,在泛型内部都是无法共工作的。那是否有办法绕过这个问题来编程,答案就是显示地传递类型标签。
public class Main<T> {
public T create(Class type) {
try {
return type.newInstance();
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
public static void main(String[] args) {
Main<String> m = new Main<String>();
String s = m.create(String.class);
}
}
代码片段展示了一种用类型标签生成新对象的方法,但是这个办法很脆弱,因为这种办法要求对应的类型必须有默认构造函数,遇到Integer类型的时候就失败了,而且这个错误还不能在编译器捕获。
public class Main {
public T[] create(Class type) {
return (T[]) Array.newInstance(type, 10);
}
public static void main(String[] args) {
Main<String> m = new Main<String>();
String[] strings = m.create(String.class);
}
}
代码片段七展示了对泛型数组的擦除补偿,本质方法还是通过显示地传递类型标签,通过Array.newInstance(type, size)来生成数组,同时也是最为推荐的在泛型内部生成数组的方法。
推荐一个牛逼的公众号
想见识更多新奇逼格好物?
想知道这些好玩的都怎么买?
想轻松避开买买买里的那些大坑?
请关注“程序员严选”10万好物等你来翻牌
↓↓↓

推荐↓↓↓
长
按
关
注
【】都在这里!
涵盖:程序员大咖、源码共读、程序员共读、数据结构与算法、黑客技术和网络安全、大数据科技、编程前端、Java、Python、Web编程开发、Android、iOS开发、Linux、数据库研发、幽默程序员等。
万水千山总是情,点个 “在看” 行不行
本网站每日更新互联网创业教程,一年会员只需98,全站资源免费下载点击查看会员权益