背景
Apache Kafka(以下称为Kafka)已在各行各业中广泛使用,作为一个成功的流处理平台,并且具有非常强大的软件生态系统。但是,它的一些缺点也给用户带来了巨大的挑战。 Automq是基于云原生体系结构实施的新一代Kafka,与Kafka完全兼容。致力于解决Kafka的最初缺点,例如效率低下的迁移和复制,缺乏灵活性和高成本,并成为新一代的云原生Kafka解决方案。
为了让读者更好地了解Automq比Kafka的优势,我们启动了“ Kafka Pain Points Special”系列,以帮助读者更好地了解当前的疼痛点以及Automq如何解决这些问题。今天,我主要在卡夫卡(Kafka)分享冷阅读的副作用(也称为追赶阅读或读取)的原理,以及Automq如何避免通过云原生架构设计从原始Kafka进行冷阅读的副作用。
冷读如何出现
在消息和流系统中,冷阅读是一个常见且有价值的场景,包括以下几点:
•确保峰值切割和山谷填充的效果:消息系统通常用于业务解耦,峰值切割和山谷填充。在峰值和山谷填充方案中,消息队列可以暂时保存上游数据以逐步消耗下游。这些数据通常不在内存中,而是需要冷读。因此,优化冷阅读效率对于改善切割和山谷填充的效果至关重要。
•批处理方案被广泛使用:与大数据分析结合使用时,Kafka通常用于处理批处理方案。在这种情况下,任务需要从几个小时甚至一天前开始的数据开始扫描和计算。冷阅读的效率直接影响批处理处理的及时性。
•故障恢复效率:在实际生产环境中,由于逻辑问题或业务错误引起的消费者失败是常见问题。消费者恢复后,需要通过快速消费积累的历史数据。提高冷阅读效率可以帮助企业更快地从消费者停机时间中恢复并减少干扰时间。
•KAFKA分区迁移期间的数据复制导致冷读数:Kafka在扩大容量时需要迁移分区数据,这也会引起冷读数。
冷读是在卡夫卡的实际应用中必须面对的正常要求。对于Automq,我们并不是要消除冷阅读,而是重点是解决Kafka冷阅读本身的副作用。
冷读的副作用
接下来,我们将分析Kafka冷阅读将带来哪些特定副作用,以及为什么Kafka无法解决这些问题。
硬盘I/O竞赛问题
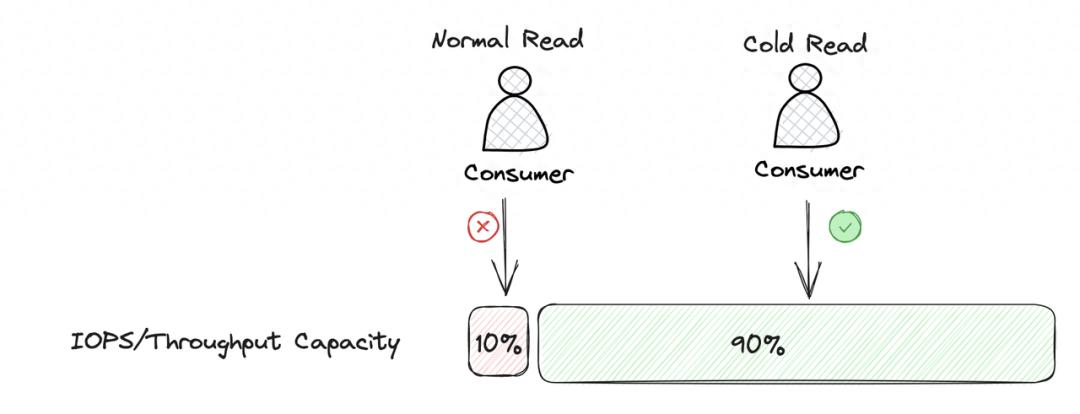
卡夫卡操作和维护中的一个重要挑战是在冷阅读过程中处理大量硬盘I/O使用情况。硬盘或云磁盘的单个磁盘IOPS和吞吐量功能受到限制。冷读数会导致大量数据从硬盘中读取,并且当某些分区数据分布在节点上时,很容易引起热点访问。对大量数据的分区进行冷读数将迅速占据单个磁盘上的IOPS和吞吐量资源,直接影响节点上其他主题分区的数据的读写性能。
Kafka无法解决此副作用的主要原因是其自己的存储实现强烈依赖于本地存储。 Kafka的数据全部存储在经纪人的本地磁盘上,该磁盘在冷阅读过程中消耗了大量磁盘I/O,当其他阅读和写入请求需要访问磁盘时,性能有限。尽管Kafka的一家商业化公司Confluent实施了KIP-405所描述的层次存储,但该问题尚未得到完全解决。在KAFKA分层存储实现中,Kafka仍然要求分区的最后一个日志段必须在本地磁盘上,并且经纪人和本地存储仍然很依赖。因此,当Kafka冷读时,无法从S3或内存完全读取数据。必须有一个请求从分区的最后一个日志段中读取数据。当日志段的数据相对较大时,争夺硬盘I/O的问题将变得更加严重。通常,Kafka使用层次存储来尝试在一定程度上减少冷阅读副作用的影响,但这并不能从根本上解决该问题。
页缓存污染
当Kafka冷阅读时,从磁盘上加载了大量数据并通过页面缓存以供消费者阅读,这将导致页面缓存的数据污染。页面缓存的大小相对有限。由于它本质上是一个缓存,因此需要将新对象添加到页面缓存中时,如果其容量不足,则会驱逐一些旧对象。
Kafka不会进行冷和冷隔离。当发生冷阅读时,大量冷数据的读取将迅速抓住页面缓存的能力并将其他主题数据驱逐出来。当其他主题消费者需要从页面缓存读取数据时,就会发生缓存失误,然后必须从硬盘读取数据。目前,阅读延迟将大大增加。在这种情况下,由于硬盘加载数据,总体吞吐性能也会迅速降解。 Kafka使用PACHE CACHE与SendFile系统调用结合使用时,在没有发生冷读时表现良好,但是一旦发生冷读数,其对吞吐量和读写延迟的影响将非常麻烦。
Kafka无法很好地解决这个问题,主要是因为它的读写模型本身强烈依赖于页面缓存来实现其强大的性能和吞吐量。
零复制块在冷阅读过程中的网络请求
Kafka使用零拷贝技术sendfile来避免内核和用户状态之间交互的开销以提高性能。但是,不可否认的是,sendfile在冷读时会带来其他副作用。
在Kafka的网络线程模型中,读取和写入请求共享网络线程池以处理网络请求。在理想的情况下,没有冷读数,当网络线程在Kafka处理后需要将数据返回到网络时,它会直接从页面缓存中加载数据并返回。整个请求响应可以在几微秒内完成。整个读写过程非常有效。
但是,如果发生冷读,则当Kafka网络线程将缓冲区发送到网络内核以编写数据时,调用sendfile需要首先将磁盘加载到页面缓存中,然后写入网络内核发送缓冲区。在此零复制过程中,Linux内核在同步系统调用中加载了从磁盘到页面缓存的数据,因此网络线程只能同步并等待其关联的数据以在继续处理其他内容之前从磁盘上完成加载数据。工作。
Kafka的网络线程池由客户端的读写网络请求共享。在冷阅读过程中,Kafka网络线程池中的大量网络线程正在等待系统呼叫同步返回,这将阻止新的网络请求进行处理,并进一步增加消费者消费的延迟。下图显示了sendfile在冷阅读过程中如何影响网络线程的处理,从而进一步降低了整体生产和消费效率。
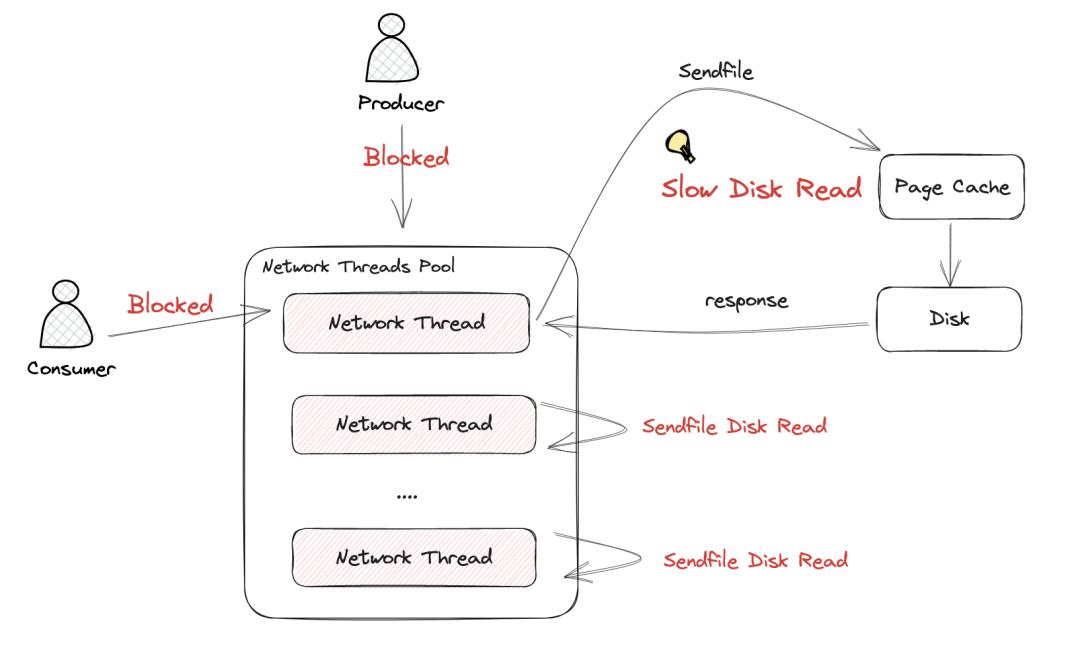
根据上述原则分析,可以看出,Kafka无法正确解决此问题的原因主要是由于其线程模型的设计。在Kafka的读写线程模型中,读写共享网络线程池。在冷读数过程中,sendfile的缓慢操作与读写核心过程没有异步分离,这导致网络线程在冷读时变成瓶颈,从而导致明显的吞吐量性能下降。
如何解决Automq中冷阅读的副作用
冷热隔离
对象存储是云上最大规模,最具成本效益和技术奖励的云服务。我们可以看到,Confluent和Snowflake正在基于云对象存储重塑自己的软件服务,从而为用户提供较低的成本,更稳定和灵活的存储功能。基于云对象存储的基本软件的重新设计也已成为当前Instra字段中软件设计的新趋势。作为一个真正的云本地软件,在设计开头确定了Automq,它需要使用对象存储作为其主要内存,从而在流场景中设计面向对象的流库S3Stream。该流存储库也是GitHub上的开源,您可以搜索automq-for-kafka。
Automq将对象存储用作主要存储,不仅带来了最终的成本和弹性优势,而且另一个非常重要的好处是,它有效地隔离了热和冷数据,并解决了与根部的Kafka Hard Disk I/O竞争的问题。在Automq的读写模型中,当冷读数时,数据将直接从对象存储中加载,而不是从本地磁盘上加载。这自然会隔离冷读,并且自然不会抓住当地磁盘 /O的i。
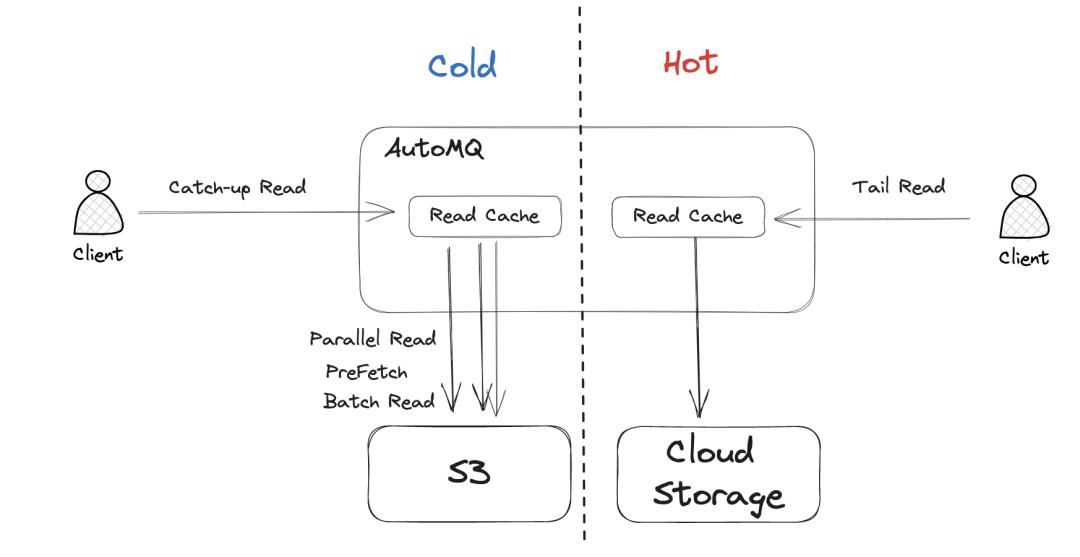
此外,基于AUTOMQ对象存储的冷读隔离将不会具有性能副作用。通过技术优化措施,例如并发,预读和批处理阅读,冷读物期间的吞吐量可以与Kafka完全相提并论。
内存的自我管理不取决于页面缓存
Automq的读写模型不依赖页面缓存,因此自然不会有Kafka页面缓存污染的副作用。尽管放弃了页面缓存的使用,但Automq并未妥协性能,主要是因为它采用了以下一系列技术措施。
使用直接I/O读写并写入裸机
Automq绕过文件系统,直接通过直接I/O读取并写入裸露的设备。这主要的好处是:
•避免页面缓存污染:绕过文件系统,自然没有页缓存污染。
•减少数据复制:使用DirectI/O直接读取仅使用一个数据副本,直接从硬件到应用程序的用户状态。
•减少文件系统开销:文件系统通常需要编写期刊以管理元数据。它消耗的带宽和IOP比实际写作要多,并且写入更长的时间,因此其性能将比裸露的设备差。
•更快的灾难恢复速度:AUTOMQ的WAL数据将保留在云磁盘上,然后将其不同步地冲洗到对象存储中。当计算实例下降时,云磁盘将自动漂移并将其安装在其他可用的机器上。 AUTOMQ完成了灾难恢复操作,即,在其云磁盘上刷新其余的WALS以将其删除对象存储,然后删除云磁盘。在此灾难恢复过程中,由于裸露设备的直接运行,可以避免文件系统恢复的时间开销,并可以改善灾难恢复的及时性。
•避免使用KAFKA数据丢失:AutOMQ需要将数据持续到云磁盘之前,然后再将其退还给客户端以成功响应。在Kafka的默认建议配置中,数据通常是异步的,以确保性能。当计算机室关闭电源时,文件系统中的残留脏页将丢失,从而导致数据丢失。
自我管理的自我纪念
在文件系统中使用页面缓存来提高性能是一种相对棘手的方法。对于Kafka来说,这意味着它不需要自己实现一组内存缓存,也不必担心其JVM的对象开销和GC问题。我不得不说,在非冷淡的阅读方案中,此方法确实具有良好的性能。但是,一旦发生冷读数,KAFKA用户模式的干预能力有限,可以进行Page Cache的默认行为,并且不可能进行一些精致的管理。因此,很难应对页面缓存的污染。
Automq完全考虑了在设计开始时使用页面缓存的利弊。在自发开发的S3Strean流媒体存储库中,它实现了对JVM Off-aeap内存的有效和自主管理。通过设计热缓存,阻塞和logcache,它可以在各种情况下确保有效的记忆读写和写作。在将来的迭代中,AUTOMQ还可以根据Flow方案进行更精炼的内存阅读和优化。
异步I/O响应网络层
Kafka的线程模型基本上是围绕页面缓存和零复制技术设计的。上一篇文章还指出,核心问题是,当冷读数时,网络线程正在同步等待磁盘读数,从而导致整个读写过程被阻止并影响性能。
AUTOMQ中未出现的问题也是由于其自身的内存管理机制实施。由于不依赖页面缓存,因此AutOMQ存储层将异步加载数据,然后响应网络层。因此,读取请求不会同步等待磁盘I/O在处理其他任务之前完成。这使得整体读写处理的处理效率更高。
冷阅读性能
冷阅读是卡夫卡的常见应用程序。在处理Kafka冷阅读副作用时,Automq不仅可以实现冷和冷的隔离,而且还考虑了确保冷阅读性能不会受到影响的重要性。
AUTOMQ确保通过以下技术手段进行冷阅读期间的性能:
•对象存储读取性能优化:通过预读,并发和缓存直接从对象存储中读取数据,从而确保总体出色的吞吐量性能。
•云本地存储层实现减少了网络开销:Automq使用云磁盘底部的多倍磁化机制来确保数据可靠性,因此在经纪人级别,可以降低复制复制的网络延迟开销。因此,与Kafka相比,它具有更好的延迟和整体吞吐性能。
下表的结果来自Automq与Kafka的实际性能比较报告。它表明,与Kafka在相同的负载和型号下相比,Automq冷读数可以确保其与Kafka的水平相同而不会影响写入吞吐量和潜伏期。冷阅读性能。
比较项目
赶上阅读期间的时间很费用
在追赶过程中对发送流量的影响
追逐峰值吞吐量
Automq
小于3ms
读写隔离,维护800 MIB/S
2500-2700mib/s
Apache Kafka
约800毫秒
互相影响
跌至150 MIB/S
2600-3000mib/s
(牺牲写)
本网站每日更新互联网创业教程,一年会员只需98,全站资源免费下载点击查看会员权益